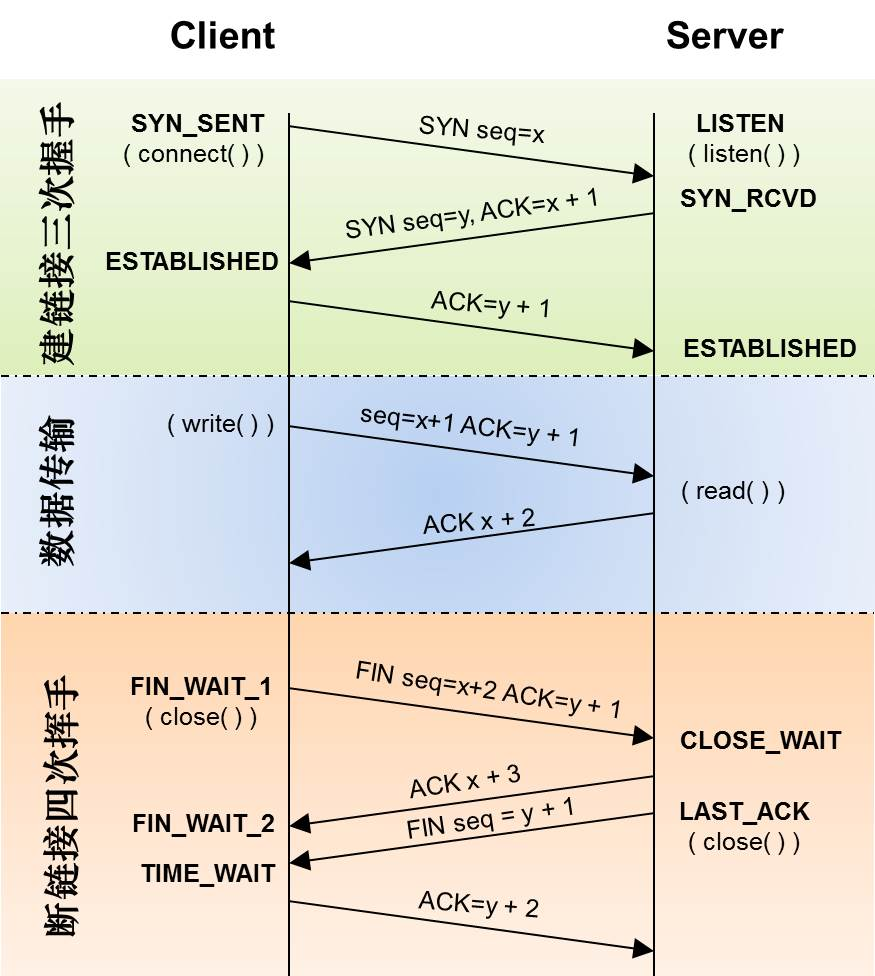
零の轨迹Sic Parvis Magna2021-11-04T05:47:44.408Zhttps://www.elietio.xyz/ElietioHexoDruid空闲连接检测 KeepAlive与MySql discard long time none received connection报警https://www.elietio.xyz/posts/99b22c04.html2021-11-04T02:55:00.000Z2021-11-04T05:47:44.408Z
当开启了test-while-idle,获取连接后会检测空闲连接,空闲的判断逻辑大致为取lastActiveTimeMillis和lastKeepTimeMillis的最大值和当前系统时间对比,如果超过了time-between-eviction-runs-millis,就认为连接空闲,需要检测,检测的第一步和上面类似,默认使用ping,成功之后再次判断连接的空闲时间,此处是通过反射获取MySQL连接的lastPacketReceivedTimeMs,ping不会刷新这个时间,如果当前时间-lastPacketReceivedTimeMs>time-between-eviction-runs-millis,则会认为连接已经超过空闲时间,于是抛弃这个连接,打印WARN日志discard long time none received connection.
/* Initialize the fields we use to disambiguate ambiguous years. Separate * so we can call it from readObject(). */ privatevoidinitializeDefaultCentury(){ calendar.setTimeInMillis(System.currentTimeMillis()); //注意此处将当前年年份减去80年 calendar.add( Calendar.YEAR, -80 ); parseAmbiguousDatesAsAfter(calendar.getTime()); }
/* Define one-century window into which to disambiguate dates using * two-digit years. */ privatevoidparseAmbiguousDatesAsAfter(Date startDate){ defaultCenturyStart = startDate; calendar.setTime(startDate); //此处年份已经比当前少了80年 defaultCenturyStartYear = calendar.get(Calendar.YEAR); }
/** * Private member function that converts the parsed date strings into * timeFields. Returns -start (for ParsePosition) if failed. * @param text the time text to be parsed. * @param start where to start parsing. * @param patternCharIndex the index of the pattern character. * @param count the count of a pattern character. * @param obeyCount if true, then the next field directly abuts this one, * and we should use the count to know when to stop parsing. * @param ambiguousYear return parameter; upon return, if ambiguousYear[0] * is true, then a two-digit year was parsed and may need to be readjusted. * @param origPos origPos.errorIndex is used to return an error index * at which a parse error occurred, if matching failure occurs. * @return the new start position if matching succeeded; -1 indicating * matching failure, otherwise. In case matching failure occurred, * an error index is set to origPos.errorIndex. */ privateintsubParse(String text, int start, int patternCharIndex, int count, boolean obeyCount, boolean[] ambiguousYear, ParsePosition origPos, boolean useFollowingMinusSignAsDelimiter, CalendarBuilder calb){ Number number; int value = 0; ParsePosition pos = new ParsePosition(0); pos.index = start; ......
parsing: { ...... case PATTERN_YEAR: // 'y' ......
// If there are 3 or more YEAR pattern characters, this indicates // that the year value is to be treated literally, without any // two-digit year adjustments (e.g., from "01" to 2001). Otherwise // we made adjustments to place the 2-digit year in the proper // century, for parsed strings from "00" to "99". Any other string // is treated literally: "2250", "-1", "1", "002". if (count <= 2 && (pos.index - actualStart) == 2 && Character.isDigit(text.charAt(actualStart)) && Character.isDigit(text.charAt(actualStart + 1))) { // Assume for example that the defaultCenturyStart is 6/18/1903. // This means that two-digit years will be forced into the range // 6/18/1903 to 6/17/2003. As a result, years 00, 01, and 02 // correspond to 2000, 2001, and 2002. Years 04, 05, etc. correspond // to 1904, 1905, etc. If the year is 03, then it is 2003 if the // other fields specify a date before 6/18, or 1903 if they specify a // date afterwards. As a result, 03 is an ambiguous year. All other // two-digit years are unambiguous. int ambiguousTwoDigitYear = defaultCenturyStartYear % 100; ambiguousYear[0] = value == ambiguousTwoDigitYear; value += (defaultCenturyStartYear/100)*100 + (value < ambiguousTwoDigitYear ? 100 : 0); } calb.set(field, value); return pos.index;
/** * Sets the 100-year period 2-digit years will be interpreted as being in * to begin on the date the user specifies. * * @param startDate During parsing, two digit years will be placed in the range * <code>startDate</code> to <code>startDate + 100 years</code>. * @see #get2DigitYearStart * @since 1.2 */ publicvoidset2DigitYearStart(Date startDate){ parseAmbiguousDatesAsAfter(new Date(startDate.getTime())); }
final Entry<K,V> nextEntry(){ Entry<K,V> e = next; if (e == null) thrownew NoSuchElementException(); if (modCount != expectedModCount) thrownew ConcurrentModificationException(); next = successor(e); lastReturned = e; return e; }
publicvoidremove(){ if (lastReturned == null) thrownew IllegalStateException(); if (modCount != expectedModCount) thrownew ConcurrentModificationException(); // deleted entries are replaced by their successors if (lastReturned.left != null && lastReturned.right != null) next = lastReturned; deleteEntry(lastReturned); expectedModCount = modCount; lastReturned = null; }
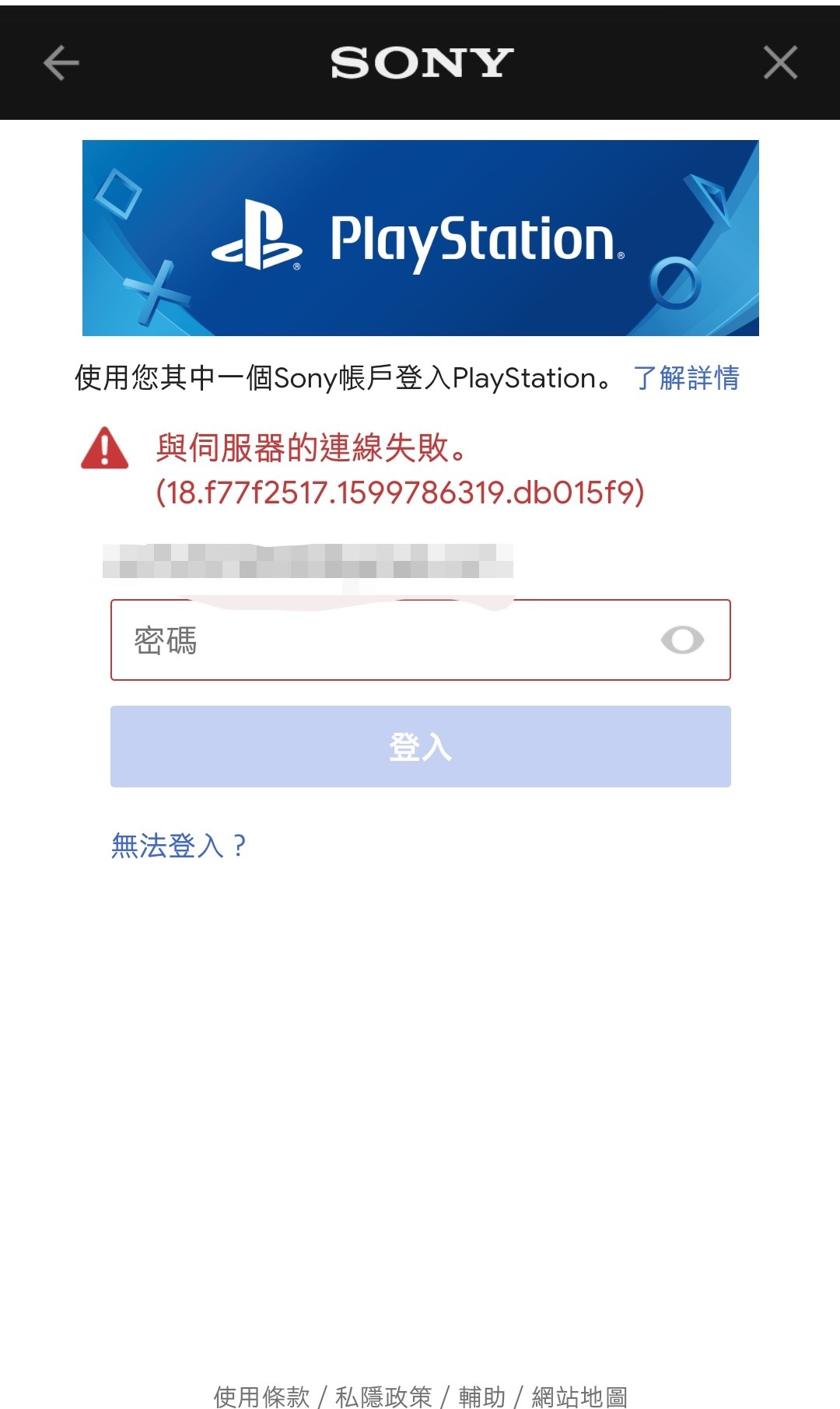
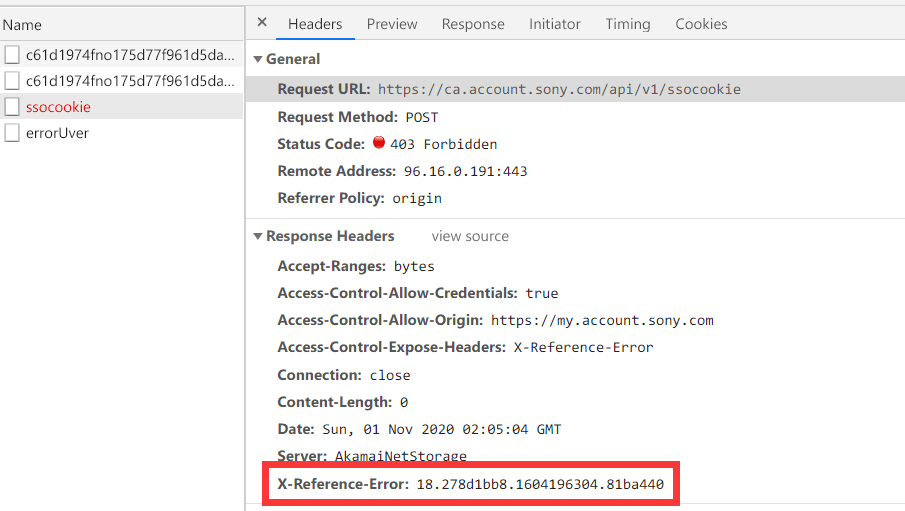
Reproduced on older Chromium v74 while works in newer browser version. I’ve send request to Galaxy to update their inner browser version. It may help but not for sure.
Problem is because we’re rejected with 403 while requesting auth cookie
Akamai server blocks requests from older browser for some reason maybe because of SameSiteCookie policy, or CORS, or maybe because Akamai’s anti-bot script does not like Galaxy browser.
Login works when user requests are handled by direct PSN server (nginx header) Login does not work when requests are handled by Akamai’s load balancer. This is why it happen sometimes, not always.
Known workarounds:
use VPN wait some time (like a day) and try to login again when there is smaller traffic.
netstat -anp|grep 1521 (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp6 0 0 172.16.72.25:18704 172.16.71.13:1521 ESTABLISHED 9229/java
而错误日志显示
1 2 3 4 5 6
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException: Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Could not get JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 0, maxActive 20, creating 1 ....... Caused by: java.sql.SQLRecoverableException: IO Error: Connection reset at oracle.jdbc.driver.T4CConnection.logon(T4CConnection.java:498) at oracle.jdbc.driver.PhysicalConnection.<init>(PhysicalConnection.java:553)
"Druid-ConnectionPool-Create-523528914" #83 daemon prio=5 os_prio=0 tid=0x00007f6d1d8d4800 nid=0x26fb runnable [0x00007f6db3ffd000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:170) at java.net.SocketInputStream.read(SocketInputStream.java:141) ...... at oracle.jdbc.driver.T4CSocketInputStreamWrapper.readNextPacket(T4CSocketInputStreamWrapper.java:124) at oracle.jdbc.driver.T4CSocketInputStreamWrapper.read(T4CSocketInputStreamWrapper.java:80) at oracle.jdbc.driver.T4CMAREngine.unmarshalUB1(T4CMAREngine.java:1137) .... at com.alibaba.druid.filter.FilterChainImpl.connection_connect(FilterChainImpl.java:150) at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1560) at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1623) at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2468)
而当前工作线程
1 2 3 4 5 6 7 8 9
"http-nio-8212-exec-7" #72 daemon prio=5 os_prio=0 tid=0x00007f6d46caa800 nid=0x26ea waiting on condition [0x00007f6db90ea000] java.lang.Thread.State: TIMED_WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000006c23e65c8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078) at com.alibaba.druid.pool.DruidDataSource.pollLast(DruidDataSource.java:1946) at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1458) at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1255)
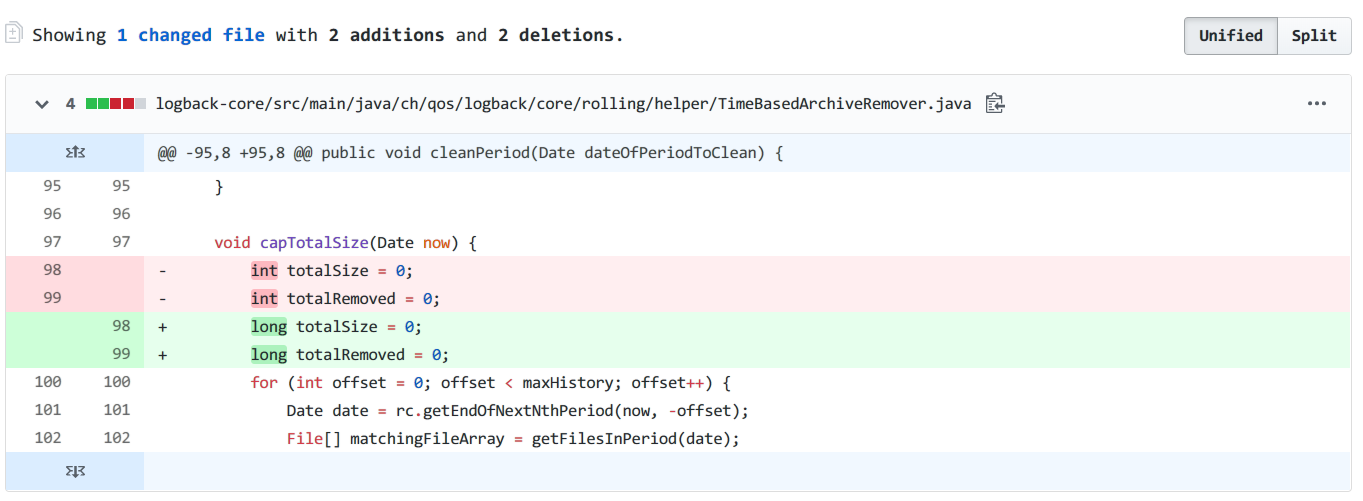
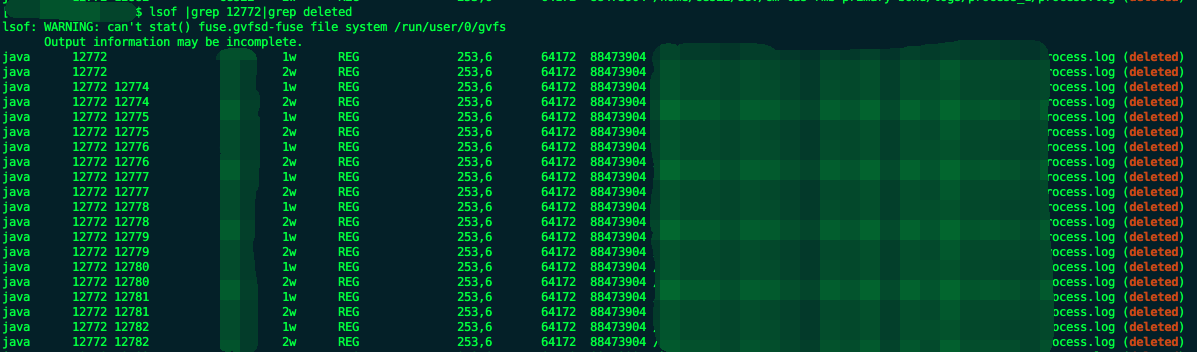
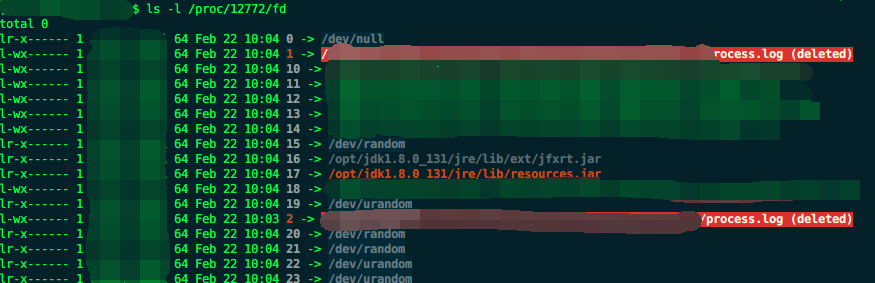
I’m using SizeAndTimeBasedRollingPolicy. When ‘%i’ file index reaches 999 it stops deleting the old files and totalSizeCap is not respected any more. This soon leads to disk full issues (as logging in my case was fast enough)
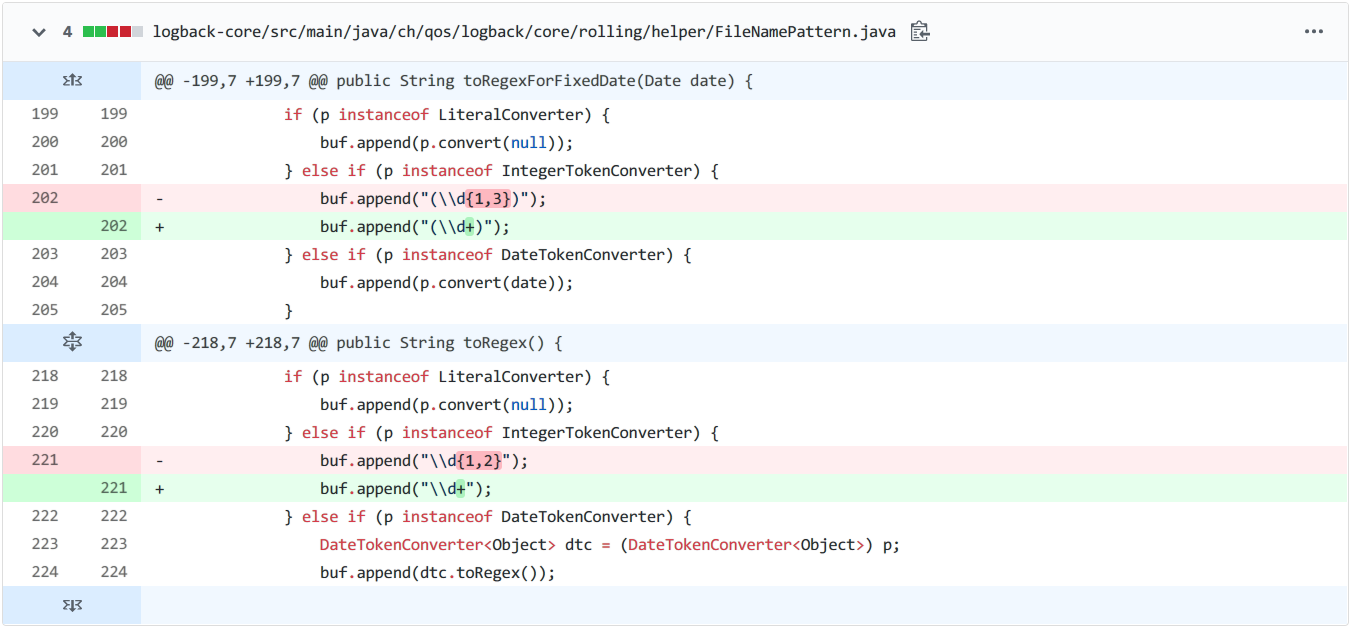
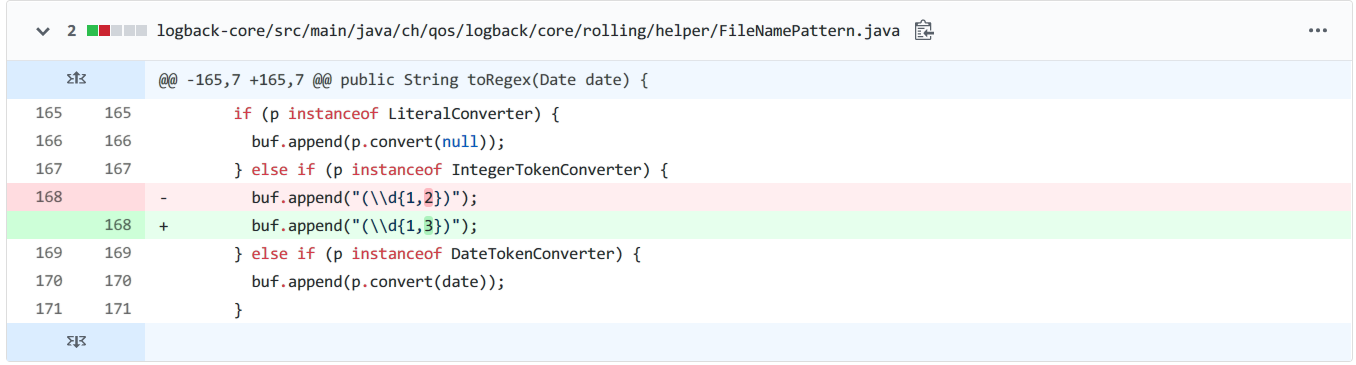
/** * Given date, convert this instance to a regular expression. * * Used to compute sub-regex when the pattern has both %d and %i, and the * date is known. * * @param date - known date */ public String toRegexForFixedDate(Date date){ StringBuilder buf = new StringBuilder(); Converter<Object> p = headTokenConverter; while (p != null) { if (p instanceof LiteralConverter) { buf.append(p.convert(null)); } elseif (p instanceof IntegerTokenConverter) { buf.append("(\\d{1,3})"); } elseif (p instanceof DateTokenConverter) { buf.append(p.convert(date)); } p = p.getNext(); } return buf.toString(); }
"IMT_328b84d5-3364-46cf-acfe-5e78de9f9cce_BL" prio=10 tid=0xada04400 nid=0x7816 waiting for monitor entry [0x9d1fe000] java.lang.Thread.State: BLOCKED (on object monitor) at com.google.common.eventbus.Subscriber$SynchronizedSubscriber.invokeSubscriberMethod(Subscriber.java:150) - waiting to lock <0xb73e5c58> (a com.google.common.eventbus.Subscriber$SynchronizedSubscriber) at com.google.common.eventbus.Subscriber$1.run(Subscriber.java:76) ......
waiting to lock <0xb73e5c58> (a com.google.common.eventbus.Subscriber$SynchronizedSubscriber) 从这个信息看确实是Subscribe的同步锁,那么继续寻找当前占有锁的线程,发现如下
"IMT_0945732d-7dc7-4d12-8e5f-c4f7e9f9f295_BL" prio=10 tid=0xa7d02c00 nid=0x68ce runnable [0x9e9fc000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.read(SocketInputStream.java:152) at java.net.SocketInputStream.read(SocketInputStream.java:122) at org.apache.http.impl.io.AbstractSessionInputBuffer.fillBuffer(AbstractSessionInputBuffer.java:158) at org.apache.http.impl.io.SocketInputBuffer.fillBuffer(SocketInputBuffer.java:82) at org.apache.http.impl.io.AbstractSessionInputBuffer.readLine(AbstractSessionInputBuffer.java:271) at org.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:140) at org.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:57) at org.apache.http.impl.io.AbstractMessageParser.parse(AbstractMessageParser.java:259) at org.apache.http.impl.AbstractHttpClientConnection.receiveResponseHeader(AbstractHttpClientConnection.java:281) at org.apache.http.impl.conn.DefaultClientConnection.receiveResponseHeader(DefaultClientConnection.java:259) at org.apache.http.impl.conn.ManagedClientConnectionImpl.receiveResponseHeader(ManagedClientConnectionImpl.java:209) at org.apache.http.protocol.HttpRequestExecutor.doReceiveResponse(HttpRequestExecutor.java:273) at org.apache.http.protocol.HttpRequestExecutor.execute(HttpRequestExecutor.java:125) at org.apache.http.impl.client.DefaultRequestDirector.tryExecute(DefaultRequestDirector.java:686) at org.apache.http.impl.client.DefaultRequestDirector.execute(DefaultRequestDirector.java:488) at org.apache.http.impl.client.AbstractHttpClient.doExecute(AbstractHttpClient.java:884) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:82) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:107) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:55) at com.netflix.loadbalancer.PingUrl.isAlive(PingUrl.java:126) at com.netflix.loadbalancer.BaseLoadBalancer$SerialPingStrategy.pingServers(BaseLoadBalancer.java:902) at com.netflix.loadbalancer.BaseLoadBalancer$Pinger.runPinger(BaseLoadBalancer.java:672) at com.netflix.loadbalancer.BaseLoadBalancer.forceQuickPing(BaseLoadBalancer.java:814) at com.netflix.loadbalancer.DynamicServerListLoadBalancer.updateAllServerList(DynamicServerListLoadBalancer.java:268) at com.netflix.loadbalancer.DynamicServerListLoadBalancer.updateListOfServers(DynamicServerListLoadBalancer.java:250) at com.netflix.loadbalancer.DynamicServerListLoadBalancer.restOfInit(DynamicServerListLoadBalancer.java:144) at com.netflix.loadbalancer.DynamicServerListLoadBalancer.<init>(DynamicServerListLoadBalancer.java:95) at com.netflix.loadbalancer.ZoneAwareLoadBalancer.<init>(ZoneAwareLoadBalancer.java:82) at org.springframework.cloud.netflix.ribbon.RibbonClientConfiguration.ribbonLoadBalancer(RibbonClientConfiguration.java:140) ......
Caused by: java.lang.ArrayIndexOutOfBoundsException: -32768 at oracle.jdbc.driver.OraclePreparedStatement.setupBindBuffers(OraclePreparedStatement.java:2673) at oracle.jdbc.driver.OraclePreparedStatement.processCompletedBindRow(OraclePreparedStatement.java:2206) at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:3365) at oracle.jdbc.driver.OraclePreparedStatement.execute(OraclePreparedStatement.java:3476) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3409) at com.alibaba.druid.wall.WallFilter.preparedStatement_execute(WallFilter.java:619) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3407) at com.alibaba.druid.filter.FilterAdapter.preparedStatement_execute(FilterAdapter.java:1080) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3407) at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_execute(FilterEventAdapter.java:440) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3407) at com.alibaba.druid.proxy.jdbc.PreparedStatementProxyImpl.execute(PreparedStatementProxyImpl.java:167) at com.alibaba.druid.pool.DruidPooledPreparedStatement.execute(DruidPooledPreparedStatement.java:498)
The 10g driver apparently keeps a global serialnumber for all parameters in the entire batch, with a “short”variable. So you can have at most 32768 parameters in the batch. I was havingthe same exception because I have a INSERT statement with 42 parameters and mybatches can be as big as 1000 records, so 42000 > 32768 and this overflowsto a negative index. I reduced the batch factor to 100 to be safe, and all iswell. I guess your update DML should have a larger number of parameters perrecord, right? (My diagnostic of the bug is just deduction from the symptoms) https://community.oracle.com/thread/599441?start=15&tstart=0>
<insertid="insertBatch"parameterType="java.util.List"> INSERT INTO table (a, b, c, d ...... ) SELECT SEQ.nextval,A.* FROM ( <foreachcollection="list"item="item"index="index"separator="union all"> SELECT #{item.a},#{item.b},#{item.c},#{item.d}...... FROM dual </foreach>) A </insert>
拼接下来实际SQL如下,类似于insert into tableA select * from tableB
1 2 3 4 5 6 7 8 9 10 11 12 13
INSERTINTOtable (a, b, c, d ......) SELECT SEQ.nextval, A.* FROM ( SELECT ?, ?, ?, ?, ?, ?, ?, ? FROM dual union all SELECT ?, ?, ?, ?, ?, ?, ?, ? FROM dual union all SELECT ?, ?, ?, ?, ?, ?, ?, ? FROM dual union all ...... ) A
]]>
<p>感觉可能昨天都跪了,一直没注意,今天晚上才发现只剩一个固态C盘了,设备管理器也找不到机械硬盘,拔了重插也不转,心塞,明明这块1T日立也就2年多啊,通电也就6000h,我对日立还特有好感的说,买了好几块了,<br>想到好多东西也没备份就蛋疼</p>
Jedis Unexpected end of stream 异常https://www.elietio.xyz/posts/ab6869b3.html2019-05-12T11:37:06.000Z2020-06-14T02:29:54.279Z
这周末版本升级遇到一个Jedis异常,其中一步是从Mysql中的临时表查找数据然后拼装key从Redis中查找对应的缓存数据并修改。然而升级过程中修数程序却抛出一个异常Unexpected end of stream意外停止。
1 2 3 4 5
redis.clients.jedis.exceptions.JedisConnectionException: Unexpected end of stream. at redis.clients.util.RedisInputStream.ensureFill(RedisInputStream.java:199) at redis.clients.util.RedisInputStream.readByte(RedisInputStream.java:40) at redis.clients.jedis.Protocol.process(Protocol.java:151) ......
]]>
<p>这周末版本升级遇到一个Jedis异常,其中一步是从Mysql中的临时表查找数据然后拼装key从Redis中查找对应的缓存数据并修改。然而升级过程中修数程序却抛出一个异常<code>Unexpected end of stream</code>意外停止。<br>
Nintendo Switch更换内存卡https://www.elietio.xyz/posts/9f2531c3.html2019-04-30T14:39:27.000Z2020-06-13T08:18:25.216Z
This above all: to thine self be true There is nothing either good or bad, but thinking makes it so There’s a special providence in the fall of a sparrow No matter how dark long, may eventually in the day arrival
使用正则表达式匹配字符串 “There” ,将包含这个字符串的行打印并输出
1 2 3 4
awk '/There/{print $0}' poetry.txt
There is nothing either good or bad, but thinking makes it so There’s a special providence in the fall of a sparrow
使用正则表达式配一个包含字母 t 和字母 e ,并且 t 和 e 中间只能有任意单个字符的行
1 2 3 4 5
awk '/t.e/{print $0}' poetry.txt
There is nothing either good or bad, but thinking makes it so There’s a special providence in the fall of a sparrow No matter how dark long, may eventually in the day arrival